
Amazon Relational Database Service
Amazon Relational Database Service is a scalable managed service for providing applications with a relational database in the cloud. The real strength — scalability. Databases are notoriously hard to monitor, back up, scale up and down.
You can absolutely spin off a database on a EC2 instance, but then it is up to you to manage administrative stuff, like managing table space, upgrades and updates, back ups etc. As long as you don’t fancy becoming a 2000s database administrator, these are boring administrative tasks which Amazon RDS does it automatically for you.
AWS RDS gives you the ability to upsize your database instances quickly and easily. Amazon RDS’s scalability as supporting long-term growth.
Supported Database Engines
Amazon RDS supports most of the common database engines that are used in a relational context:
- Amazon Aurora
- PostgreSQL
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
Of all these, Amazon Aurora has the largest feature set as is a database product developed by Amazon followed by PostgreSQL and MySQL
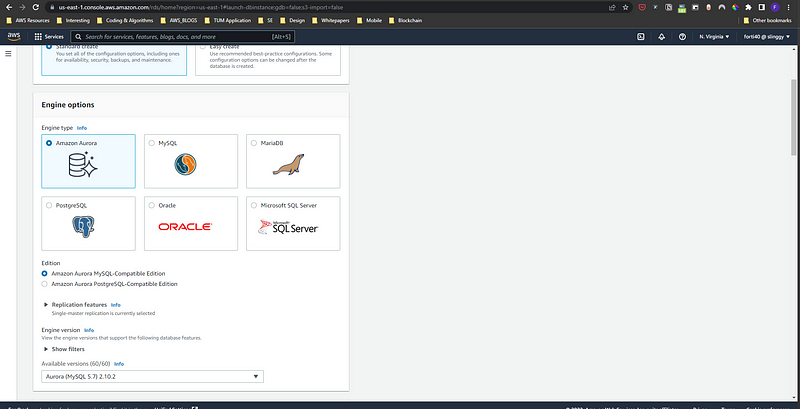
Available database engines when creating an instance from AWS Management Console
Backing Up Amazon RDS instances
Amazon RDS gives you two different options for backing up and restoration of databases:
- Turn on automated backups. This will allow you to do point-in-time recovery. RDS will back up daily with a default retention period of seven days.
- Perform manual snapshots of your database at any time and save those snapshots as long as you like.
Multi-AZ Configuration
The ability to have a read replica in another availability zone. Enabled by clicking Yes next to “Create Replica in Different Zone”.
Enabling this feature means:
- Automatically provision another database instance on other AZ.
- Set up synchronous replication from the primary ( master) database instance to the other instances.
- Provides automatic failover from the primary instance to the secondary instance in case the primary instance has a problem
This features are intended only for disaster recovery. The second database instance will never be accessible unless, the primary one fails. Failing over to the Secondary Instance happens only in this cases:
- Loss of network connectivity to the primary instance
- Disk failure of the storage volume of the primary instance
- Failure of the database instance itself
- Overall availability zone failure on the primary instance
This failover takes less than a minute for Aurora and less than two minutes for other database engines. AWS will update DNS entries pointing at your previous primary instance — which has now failed — to point at the secondary instance.
Read Replicas
On the other hand read replicas are used for improving performance. This is the preferred way to scale out your Amazon RDS instance when a significant portion of your database traffic is read-only.
After setting up the read replica, data is replicated to it asynchronously. When you write to the primary instance, the updated will eventually updated on all your replicas as well.
Connecting to the read replicas is not automatic, you’ll need to update your applications to use the DNS entries of these read replicas. If you don’t tell your application to use replicas they won’t be used.
Amazon Aurora
Amazon Aurora is a relational database developed by AWS that has the largest features set in RDS. It gives a lot of redundancy and scalability “for free”. It also provides specific compatibility with MySQL and PostgreSQL.
Amazon Aurora is automatically multi-AZ because by default it has replication occurring across availability zones. Amazon Aurora also comes with a flavor called Aurora Serverless. It automatically scales up or down based on application load without explicitly specifying and managing the database capacity.
By Fortan Pireva on May 3, 2022.